Not Only SQL has been around for a long while and often we look at making it a replacement for our existing database. But it is called not only sql for a reason. In most cases we want to go for the ‘keep it simple’ approach and limit it to one database. However, there is also the saying of the right tool for the right job. So in this blog I’ll not try to compete sql and nosql with each other. But I’ll try and highlight some of the strengths of them and how using multiple databases could actually be a good thing.
Best of both worlds
SQL relational databases have been around for a long while and have proven their use. They are a good tool in the database world. I like to look at them as the one tool that fits all choice. Because they have structure, data security, can handle large amounts of data and have relational data.
In the olden days people started with writing database schema on paper. SQL databases have been designed to host this paper structure and do this well. In these schema’s you have simple relations and well structured data. This is because working on paper did not make it easy to have too many relations and complex changing data as it would make it less readable and your erasers would run out rewriting schema’s all the time.
Document databases
The first set of databases we’ll look at, are document databases. These are databases designed to have less structure, as in technically none. They are designed to hold large amounts of data and have a free flow structure. When SQL datasets become larger and more complex, we tend to have larger execution times as the amount of joins might grow and more amounts of data have to be read. This is also why data warehousing exists as we denormalized data and pumped this data to be queried and used in a different manner. Document databases are designed in a similar way as the norm here is to denormalize more and have all data in single documents. This limits the amount of joins and makes it accessible faster.
These types of databases also don’t work structured data. So any field can be optional or a different type. This is something that is not the case in SQL databases and that they handle less well as you could have columns with a lot of NULL values. You also can’t really change the type of column value as in a document database. This is because the structure needs to be defined in the database schema.
Document databases however don’t have relations. So if you do want to separate data a bit more, you’ll need to build them in yourself. Which is a hassle, as you would need to look at other collections and change/delete data manually. We also tend to want structure at the end of our project and we built in some sort of schema in it anyway. Which is easier in SQL databases as they were designed to do that. Data also tends to be more protected in SQL databases as they are ACID compliant where as most Document databases are compliant on a document basis which is fine in most cases but this should be discussed in the scope of your project.
Practical example
Ok, I hope this was not a bit too much of a pro/con list but rather that they both have their uses. So let’s go with a more practical example. I’ll try and build a fictional project that will use all three types of databases I’ll mention here. And hopefully show that each database has its uses.
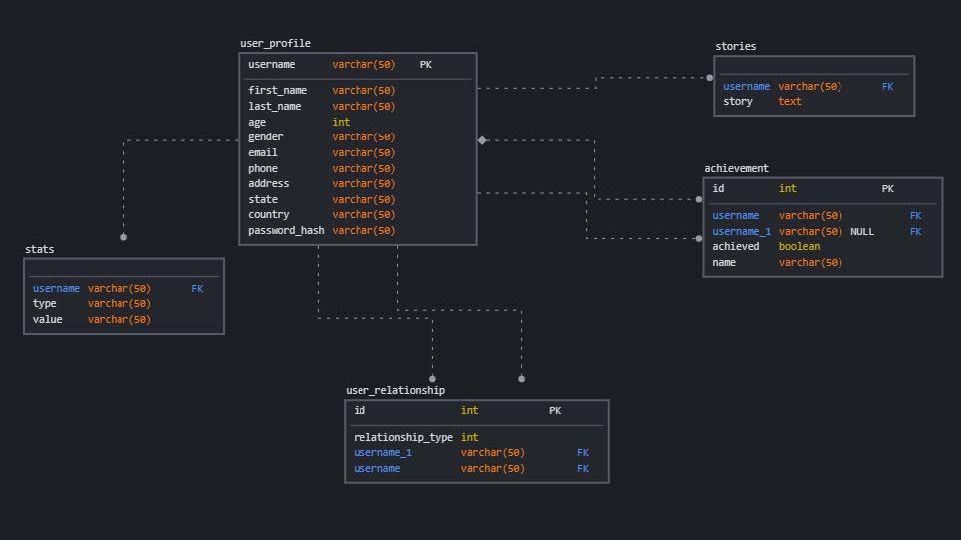
So we want to start an rpg-like dating app called DQuest. We have some personal info that is required and should always be correct and securely stored. And we want people who know each other to be able to insert their relative relationship to one another. We get something simple like this.

Generated on following site: https://app.sqldbm.com/PostgreSQL/Draft/
Ok, our site is becoming more popular and developers thought of a few new features. They want to add achievements, stats and personal adventure stories. However these are not required. In the future we might want to have users create their own achievements etc.
We could create something like this in sql.

Ok this is still not really complex but we can see with each feature we’ll need to have more joins. And we need to add in a certain structure to hold variable data for stats as they could be anything. We could denormalize this data into a document and just collect it that way. As this data is also less important to be completely acid compliant. Documents are mostly generated in a json-like way (for example mongodb uses bson). I generated a few documents like this.
[
{
“id”: “userid”,
“stats”: {
“carry_weight”: 300,
“dates_had”: “dozens”
},
“stories”: [
“Once upon a time this dude lifed 300 grams and got ripped”
]
},
{
“id”: “userid1”,
“stats”: {
“carry_weight”: “20 pounds”,
“dates_had”: 2,
“fluent in elvish”: true
}
}
]
We can see here that certain fields are not required or that some achievements can differ widely in name and value type. These empty fields result in null rows. Although in our case not many and the variable can also be handled by the sql databases. Let’s say in the future though we want to have some stats accompanied with a picture. We would need to update the schema and add another optional row. In json we can easily adapt the schema and continue development.
{
“id”: “userid”,
“stats”: {
“carry_weight”: “20 pounds”,
“dates_had”: 2,
“fluent in elvish”: true,
“pick of destiny”: {
“image”: “assests/img1.jpg”,
“damage”: 12
}
}
}
]
Which would require some schema updates in SQL. However, as I said, we like to strife for structure as this is easier down the line. And so If we can have it, why not add it. Achievements are most likely generated by the app. So we know the names and this will not change, so why not add it here. It is also more important that we have this acid compliant as we want to use this to match people.
Lastly, as mentioned before, we have relationships which is something of a hassle in document databases. We have users having relationships with users which in json would be something like this:
{
“id”: “userid”,
“relations”: [
{
{
“type”: “friend”,
“userid”: “userid1”
}
}
]
},
But we can see that if we wanted to get some general stats about userid1 like its name etc. We would have to either search the collection for this document or we would need to denormalize data and add these things inside the relations structure. But then, when we update one user we would have to search for all documents and update manually. This is something already present in SQL databases, as it is designed to have built in relationships and auto updating features.
Graph Databases
I’ve said that SQL databases are the best of both worlds and now the strength of SQL has been its relationships and database structure. Well, beside document databases we also have column, key-value and graph databases. Column and key-value are more focussed on data, similar to document databases. Graph databases however focus on the relationships between data. SQL databases have relationships but they were intended to be mostly simple one to one or one to many types. Also if we create more and more and deeper relationships, this tends to slow down query speeds as we have more and more joins.
So let’s view our practical example again as this might showcase the need for this type of database more. Our developers want to add a friends of friends feature or a people you might know feature. We have this setup in sql. We have a relationship table in our schema.

So getting all your friends is easy. Getting friends of friends is also still doable but requires an extra join. Let’s say our user also knows these people. So he wants to see a level higher. Friends of friends of friends. As you can tell each of them becomes a growing number of joins. Which is not what sql was intended for.

For this example I used an example from neo4J https://neo4j.com/graphgists/first-steps-with-cypher/
In theory we can do a lot with relationships, like find people with similar interests and similar friends. These types of databases give a fresh look into your data as we focus on a different aspect of it.
After thoughts
So I hoped I’ve shown you that databases are not limited to this one story. But rather, that just like Batman we can build a tool belt with a tool for each case. Do note that you can mix and match these technologies as needed by your project. But having three different types of databases requires more knowledge and maintenance, etc..
Each database has their strengths and weaknesses and it is up to you to decide what fits best for your project.